扫描的图片或材料如何在保持版式的情况下,提取文字并修改呢?想快速搜索印刷文件中的关键词,怎么实现?只想识别文档中的一小块文字区域,如何选定?
现有的文字提取工具,大多数会将文字直接提取出来(如图)。但是当我们在修改一份公文或者设计稿的时候,希望保留版式,在原有版式上进行修改,怎么办呢?

以上为微信文字识别示意图
福昕来帮你!福昕高级PDF编辑器支持在最大可能保持版式的基础上,直接在原有版式上进行文字提取并修改进行文字提取并修改,而且在全新升级的2023大版本中,还支持选定区域文字识别。具体如何操作呢?跟着小福一起来看看吧!

我们打开基于纸质扫描或图片的PDF文档时,福昕高级PDF编辑器能自动检测并弹出信息框,提示您是否进行OCR文字识别;

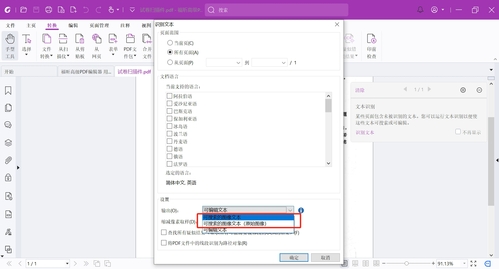
我们也可以在导航栏“转换”中随时进行手动识别,这里可以选择当前文本识别、多个文本识别、或者指定区域文字识别。

在弹出的对话框中,选择需要识别的页面范围、文档语言以及输出设置。

在“输出”类型中,若选择“可搜索的图像文本”或“可搜索的图像文本(原始图像)”,则识别后图片上的文本可以被选择并且可以搜索到关键词文本,也可以选中文字后右键进行高亮、加超链、复制等操作,可以用于查阅资料但不想修改内容的时候用;

(动图)
若选择“可编辑文本”,则识别后编辑文本时图片上的文本也可支持编辑,且识别后的文本最大可能地保持了原有的版式。
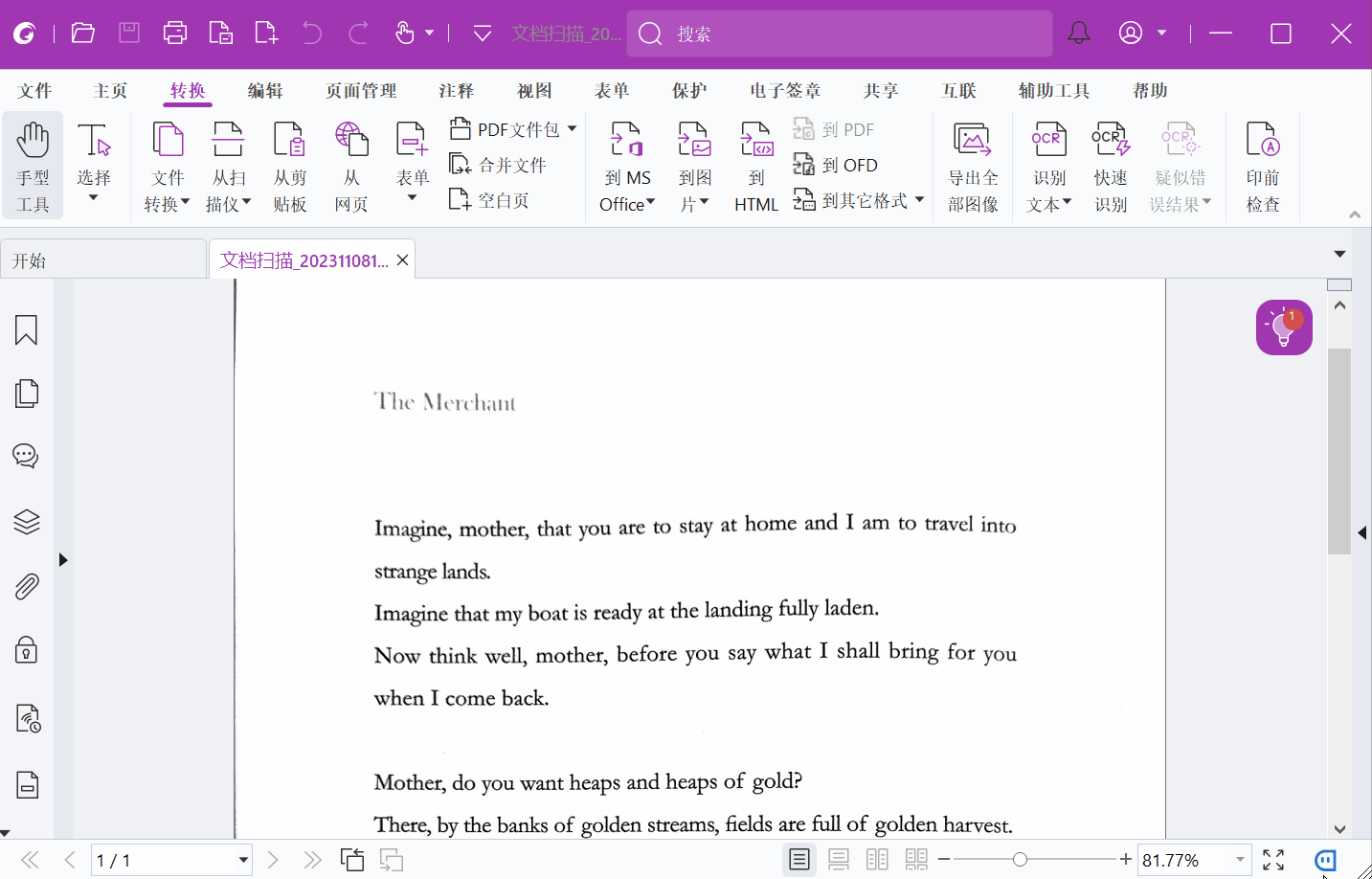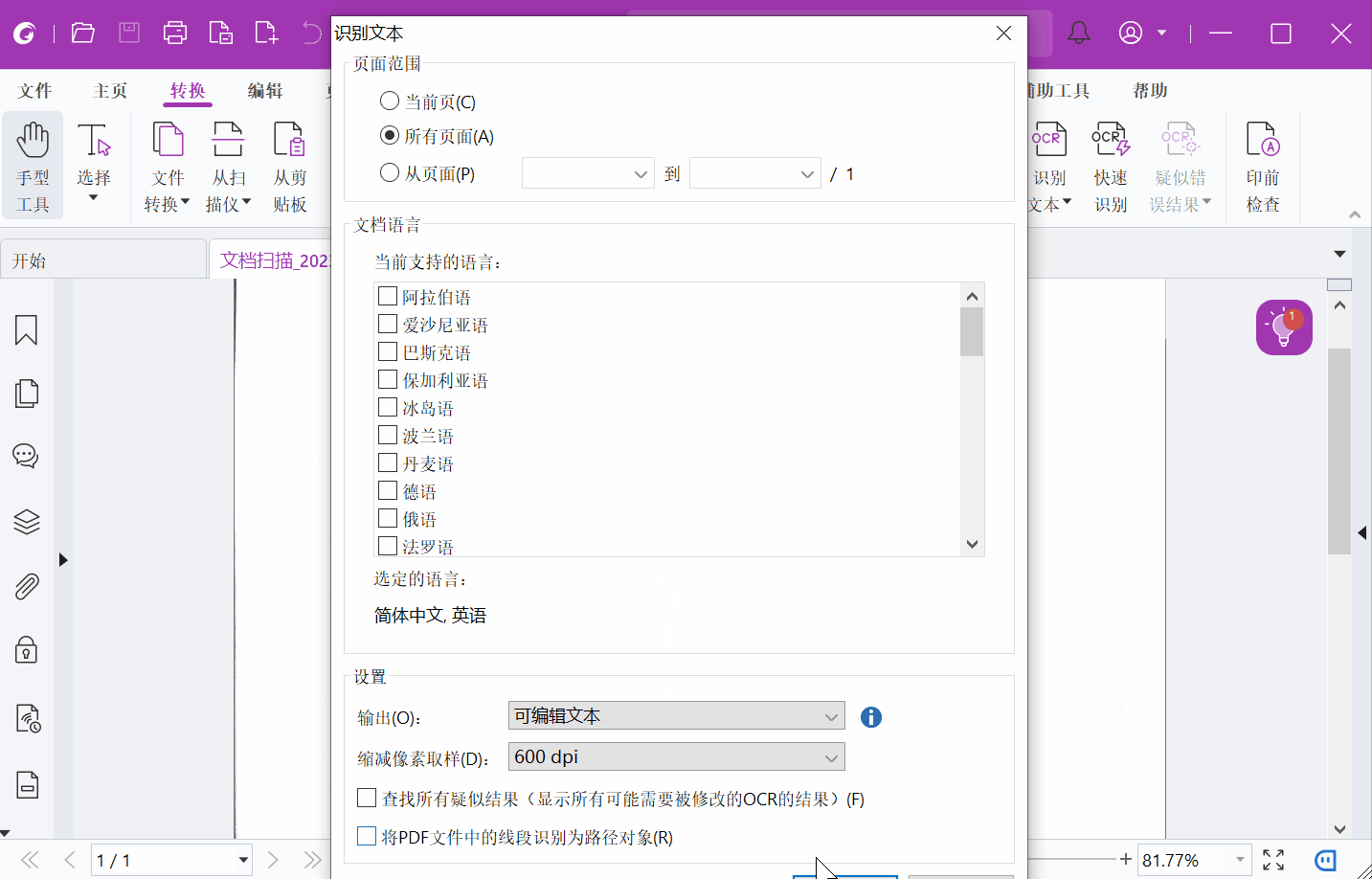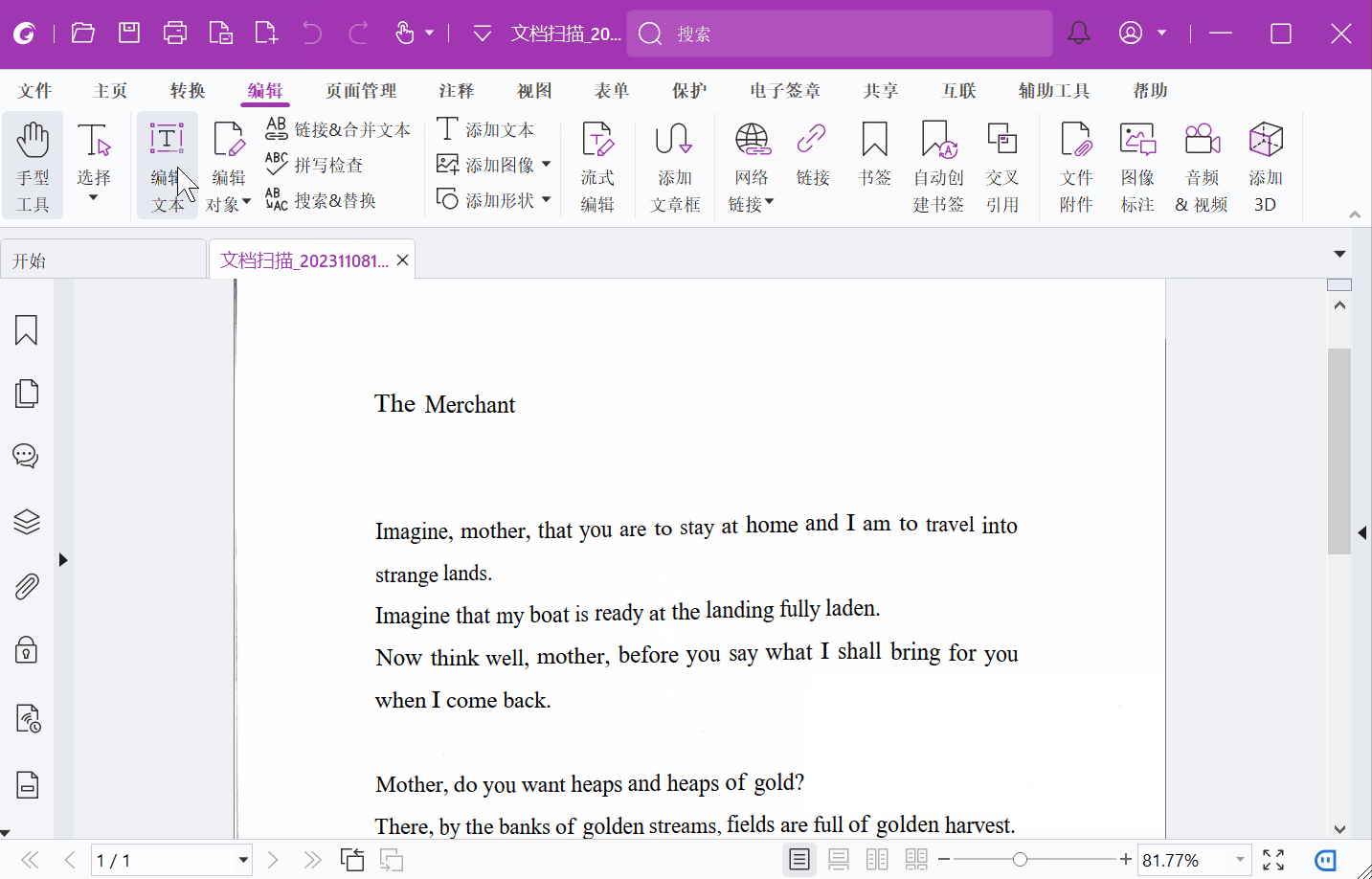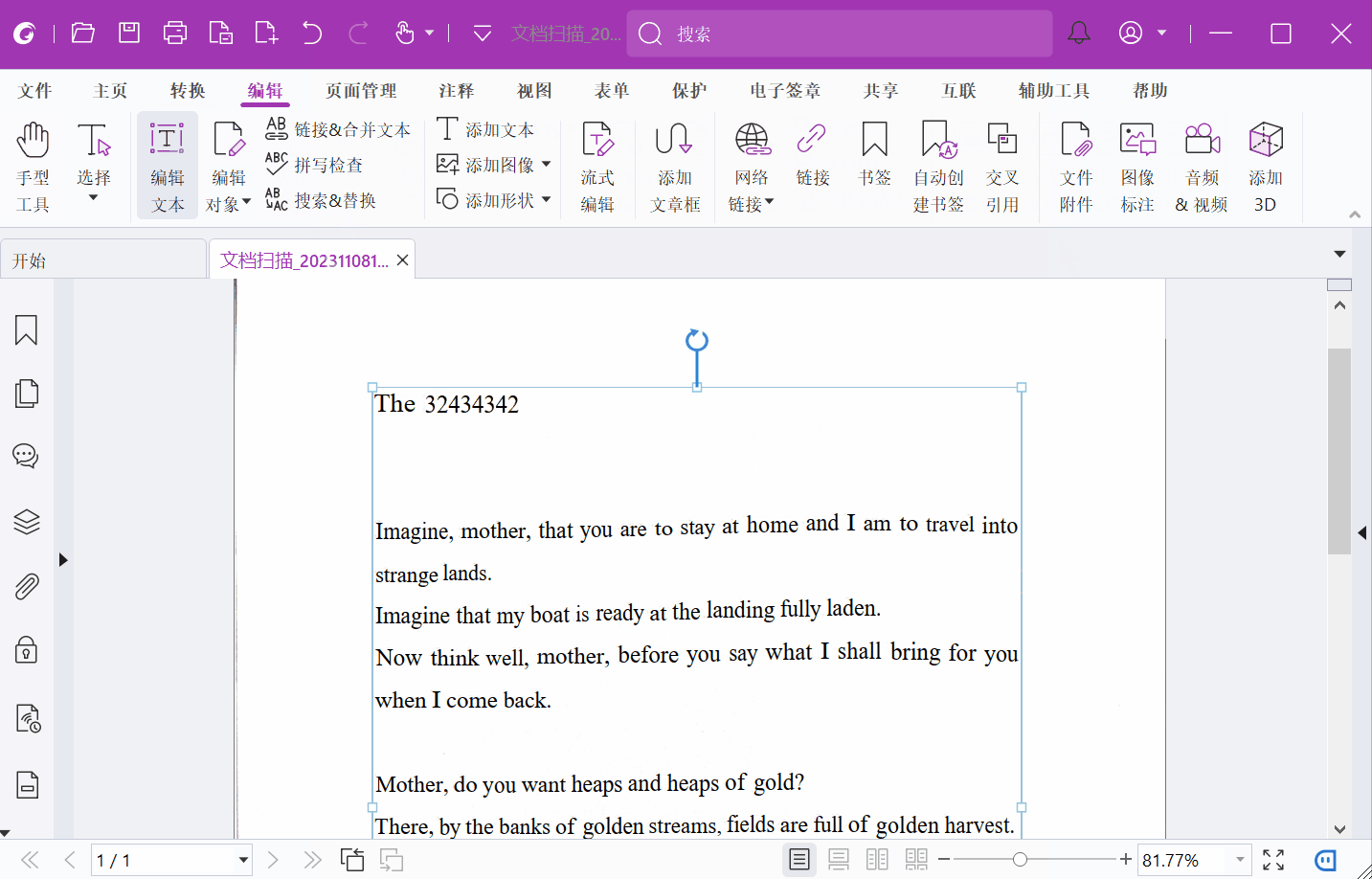
选择“可搜索的图像文本”或“可编辑文本”时,您可以在“缩减像素取样”项中为输出内容设置像素值,以在OCR过程中压缩文档中的图像和减小文件大小。

您也可以通过“快速识别”按钮,使用程序的默认设置、或最近一次通过“识别文本”命令识别文本的设置,快速进行文本识别。
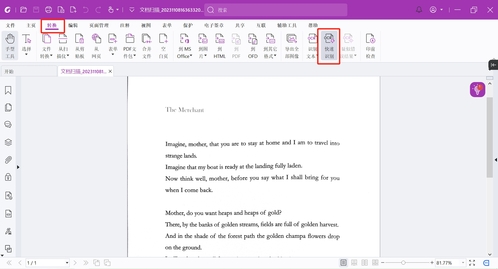
如果是指定区域识别,我们点击“转换”>“识别文本”>“选定的区域”,勾选一个区域后右键“识别选定的区域”即可。
(动图)
这里为大家进行图片OCR的拓展说明;
大多数时候我们只收到一张图片,如何创建成PDF文档并OCR识别呢?
1、我们可以点击“文件”>“创建”>“将文件转为PDF”,选择文档中的图片创建为PDF文档再进行识别;或从剪贴板直接将截图或复制好的图片创建成PDF文档,再进行识别;
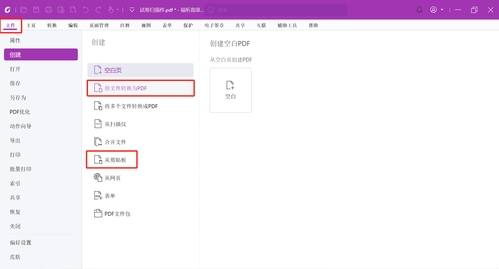
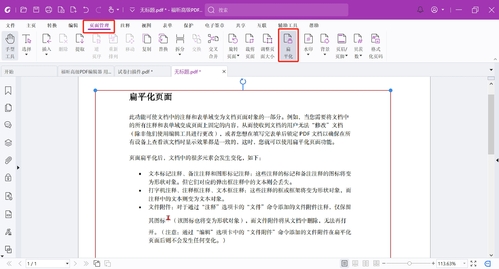
2、当我们创建了一个空白PDF文档,直接截图粘贴了一张图片到文档中,这时我们需要先进行扁平化处理,再进行OCR识别。点击“页面管理”>“扁平化”,即可将选定的页面进行扁平化处理。